
Introducing Octo
Octo is a YottaDB plugin for using SQL to query data that is persisted in YottaDB’s key-value tuples (global variables).
Conforming to YottaDB’s standard for plugins, Octo is installed in the $ydb_dist/plugin sub-directory with no impact on YottaDB or existing applications. In addition to YottaDB itself, Octo requires the YottaDB POSIX plugin. The popularity of SQL has produced a vast ecosystem of tools for reporting, visualization, analysis, and more. Octo opens the door to using these tools with the databases of transactional applications that use YottaDB.
Background and Motivation
At the core of YottaDB is a hierarchical key-value data-store accessed and manipulated by native imperative programming APIs in M and C, which are in turn wrapped to create APIs in other languages such as Go, with more to come.
This approach is well-suited to so-called transactional systems – applications whose primary objective is to change the database state. Examples include:
- Core banking systems, the systems of record for bank balances
- Electronic health record systems
- Library systems, for tracking the locations of items, loans, due dates, etc.
- Election systems for registering voters and counting votes
The imperative programming model works well for transactional systems, because transactions involve state changes with associated rules, which are easily encoded as actions. In other words, imperative programming works well when the “how” to accomplish a desired outcome can be articulated clearly.
There is another class of systems for which the imperative model does not work well, where even though the “what” of a desired outcome can be articulated, the “how” is not clear.
Consider a candidate for the Rhinoceros Party who wants to spend a morning campaigning by knocking on doors in the Transylvania primary election. From the voter record dataset provided by the State, he wants to target members of the Rhinoceros Party in his precinct who have voted in at least three of the last ten primary elections. He wants the results grouped by street and then by even and odd numbered addresses so that he can walk up one side of a street and then down the other. To allow him to affably greet whoever answers the door at each address, he wants the names, genders, and ages of all voters at the selected addresses, regardless of whether they are members of the Rhinoceros Party.
While the “what” is clear, the “how” is not. Should he first screen for membership in the Rhinoceros Party? If Rhinoceros Party members are a minority of the electorate, this would be a good strategy, because it would whittle down the numbers considerably, but if they are in a majority, a better strategy would be to first screen those who voted in at least three of the last ten primary elections, as often only a minority of an electorate votes in primary elections.
Query languages allow one to specify the desired output, letting the computer figure out out how. There are many query languages (e.g., see one list) but the one most commonly used, because the data of many applications fits the relational model, is Structured Query Language or SQL.
How does Octo work?
Octo must be told what tables (relations) are defined, and how to access the data for each column of each table. While some data is likely just a value stored in the database (each voter’s name, address, gender, registered party affiliation, etc.), other data must be derived or computed such as, a voter’s age, whether a voter has voted in three or more of the last ten primary elections, and whether a door number is even or odd.
Octo’s Data Definition Language (DDL), based on SQL-92 and extended to allow the locations for data to be specified, maps tables and columns to global variable nodes, pieces of a global variable nodes, or computed values of functions.
Octo compiles the DDL into an internal binary form, and stores the compiled DDL in global variables. Global variables that Octo uses all begin with ^%ydbocto and Octo can optionally use its own global directory for its global variables. This global directory separation means that, with some caveats, Octo can operate with read-only access to an application database.
For example, Octo can be made to operate with a BC replication instance, on which the only updates permitted to the application database are those the local Receiver Server receives from an upstream Source Server.
When Octo receives an SQL query it converts the query into a canonical form. Its lexical analyzer for SQL queries is generated using flex, followed by a parser generated using Bison. Octo then converts the parsed query into a canonical form, generating M code for the query from code templates, if such M code does not already exist. Generated M routines have names derived from hashes of the canonical forms of the queries, e.g., %ydboctoP48C7NDA7tps6jVF1Ga7hS3 – names that will not clash with application routine names. As YottaDB compiles M routines to object code for execution, Octo SQL queries run as native machine code with direct access to the database.
Octo performs optimizations both in deriving the canonical form and in code generation. As performance optimization is a journey, not a destination, Octo has a set of optimizations today, and will have more tomorrow.
Client Access
Although Octo supports running queries and getting results on the server (by running the octo executable from the shell), a more common use pattern is for client applications running on their own systems to send queries to the server and to get results over a network, using a protocol such as JDBC or ODBC. Databases typically provide JDBC and ODBC software drivers that run on client systems to expose a standard API for client applications to call. These drivers run on “wire protocols” typically layered on TCP/IP.
Octo adopted the wire protocol of the popular free / open source relational database PostgreSQL. rocto, a listener for the PostgreSQL wire protocol, can be configured to listen at a TCP port. Leveraging the PostgreSQL wire protocol means that Octo does not need to develop its own set of ODBC/JDBC drivers, and clients can use existing PostgreSQL drivers.
In keeping with YottaDB’s free / open source ethos, we test and support Octo with SQuirreL SQL at this time, but will likely add others in the future.
Mapping
Although one reason for the popularity of NoSQL databases is the fact that they do not impose rigid schemas, any successful large application will have a schema – even if an informal schema, and even if not normalized. While generating a DDL for an existing application can be done manually, generating it automatically is likely to be more robust and maintainable for long-lived applications.
As an example of an automated mapping tool, YottaDB developed OctoVistA, a tool for automatically generating the DDL for any VistA implementation that uses VistA’s Fileman to manage the database rather than directly accessing global variables.
Representative Configuration
The diagram shows a representative configuration of Octo in a production deployment of VistA.
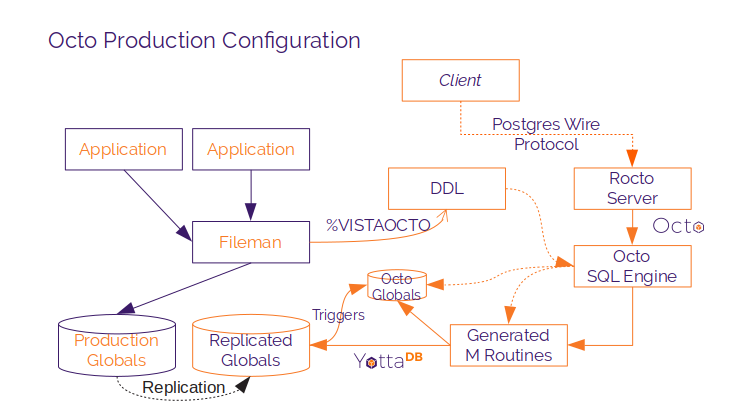
Imperative application logic uses Fileman to access and update production globals in a production instance, shown with orange letters inside purple figures. YottaDB SI replication is used to create an instance for decision support using Octo, shown with purple letters inside orange boxes. %VISTAOCTO generates a DDL from Fileman, on either the originating primary instance or replicating secondary (Octo) instance. On the Octo instance, the Octo SQL engine reads and compiles the DDL, storing the compiled DDL in global variables.
When the Octo SQL engine receives a query, either on the server or from a client, it compiles the query and converts it into the canonical form. Using the compiled DDL, it generates an M routine for the query if one does not exist. When the M routine runs, if any cross references are needed, it generates them and creates triggers to maintain the cross references as further updates are replicated to the database.
Status and Roadmap
At present (early July, 2019), following an Alpha test with an intrepid user, Beta test releases of Octo are available, and YottaDB is working with a core set of Beta testers. Based on their feedback and on additional automated testing we will follow up with a production release of Octo, which we anticipate in late 2019.
Octo currently supports read-only access from SQL, and is therefore useful in conjunction with imperatively programmed applications which update database state. As SQL supports all “CRUD” (Create, Read, Update, Delete) database operations, following the release of a production grade version of Octo for reporting (i.e., read-only access), we intend to work towards versions that support read-write access as well.
Although SQL-92 (also known as SQL2) is the standard that is most widely supported by relational database management systems, there are newer versions of the standard. Octo supports mostly SQL-92 with some extensions from newer standards, and our plan for the future is to enhance Octo with functionality from the newer standards.
As PostgreSQL is the leading free / open source relational database management system, its footsteps are good ones for Octo to follow. Given the plethora of relational database management systems, YottaDB intends to add compatibility with an increasing set of such systems over time.
Octo’s strength is the fact that it is built on YottaDB. Access to and control over YottaDB’s global variables gives Octo users the ability to fine-tune the storage for application needs. For example, a primary database could be have its global variables organized for scaling of a transaction processing database. Replicating to another instance using a schema change filter as supported by YottaDB replication could be used to create an instance with the same relational schema, but completely different global variables, optimized for decision support.
We appreciate your company as we embark on this journey of adventure in the land of databases.
Published on July 07, 2019