SQL on VistA and More
Octo Delivers SQL on VistA
Octo is a SQL database whose tables are in a YottaDB database. YottaDB is the same database technology that runs many of the world’s largest real-time core-banking systems, as well as, large-scale electronic health information system, including variants of VistA from the Department of Veterans Affairs, CHCS from the Department of Defense, RPMS from the Indian Health Service, as well as several others.
Technology
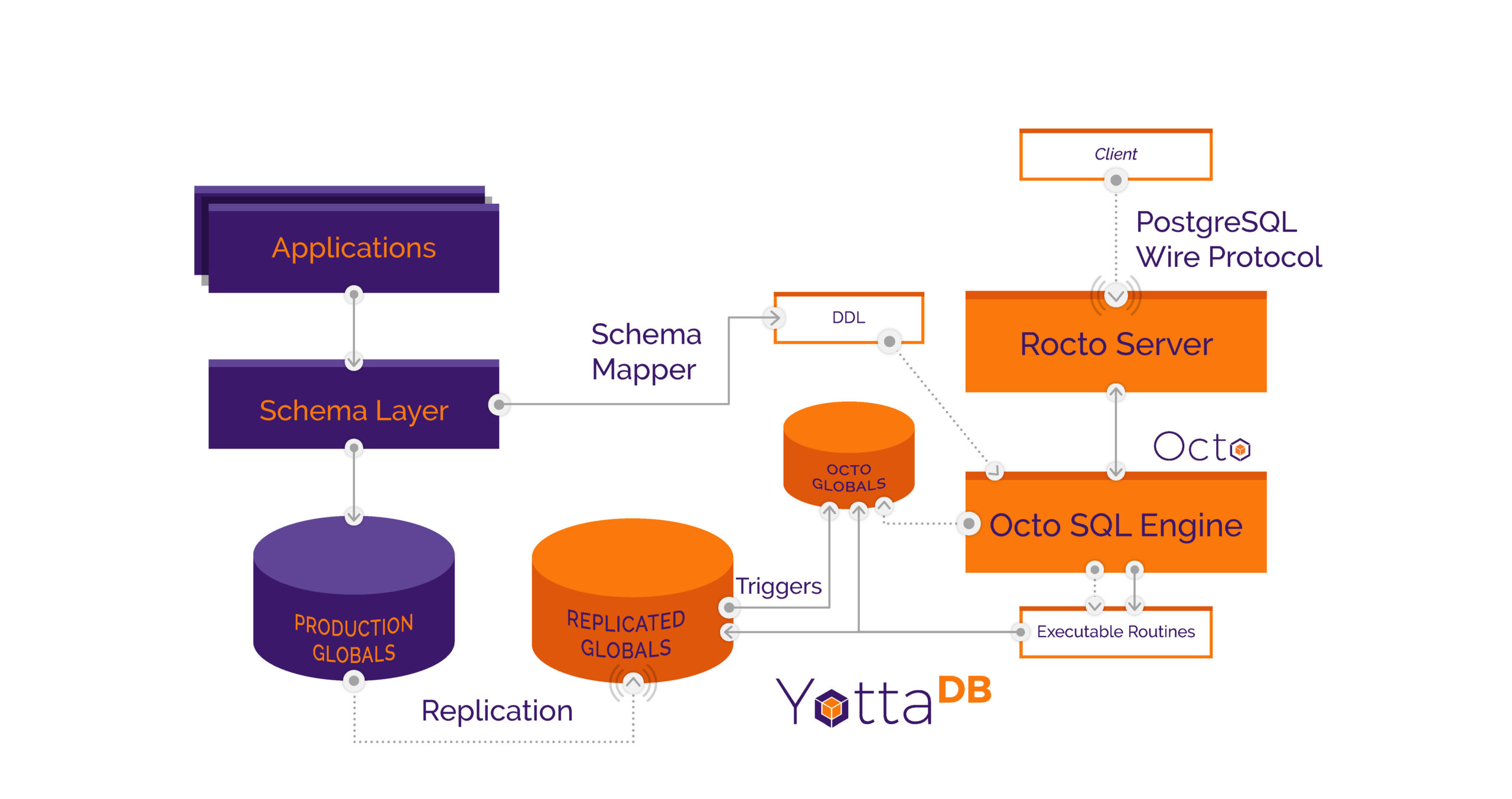
Octo is a SQL database whose tables are stored in the hierarchical key-value nodes, called global variables, of a YottaDB database.
Deployment
The figure above illustrates Octo used with an application like VistA. The production system is shown with orange letters in purple boxes, and the Octo system with purple letters in orange boxes. In the case of a large scale ERP system like like VistA, individual applications typically do not directly access the database, but instead go through a schema layer, Fileman in the case of VistA.
Reporting and analytics should not be run on a production system. This is because a real-time production system has response time service levels it must maintain. An analytics or reporting query can, depending on the query, “churn” the production database, impacting real-time response times. So, analytics and reporting should be run on a copy of the real-time production system.
The production system can run any database. We of course think that the best database to use is YottaDB, but for an application like VistA, it can be GT.M from which there is real-time replication to YottaDB, or Caché/IRIS from which replication can be established using journal file extracts so that replicated data is near real-time (i.e., minutes). Near real-time extracts from journal files is also the replication technique for applications using a database like MongoDB.
For SQL access, Octo requires the application data, but does not require the application code, except for functions needed to convert data in application specific formats to formats that are meaningful to SQL queries. For example VistA uses a special timestamp called a “Fileman date” and Octo would require that code, or functionally equivalent code, to make a column of Fileman dates accessible to SQL as ordinary dates.
Apart from application data, the other key information that Octo requires is the schema, in Octo’s Data Definition Language (DDL), which is ordinary SQL-92 DDL enhanced with functionality to map tables to global variables. The mapping capability is very flexible: for example, different parts of a global variable sub-tree can be mapped to columns of single table, and conversely, a table can contain columns from different global variables. A column other than a key column can also be a function that returns a value.
Use Cases
The most common use case for Octo is real-time reporting and analytics of applications running on YottaDB or other key-value databases from which application updates can be replicated to YottaDB.
However, Octo has uses beyond real-time reporting and analytics. Separation of application code from application data means that reporting and analytics can be done in a “clean” environment. Furthermore, Octo lends itself to simple DevOps, including deployment in containers and virtual machines. Applications include:
Application data can be isolated from applications for analytics such as forensics.
An enterprise scale application will often have interfaces and configuration complexity. The simple configuration of an Octo instance and its focus on data rather than application code means that deploying Octo is likely to be simpler than deploying complete applications.
Applications deployed with proprietary licenses can prevent the application code from being deployed to multiple environments, or may incur additional costs. As application data is typically owned by the licensee rather than the licensor, that data can be freely moved to additional environments for reporting and analysis. Furthermore, while there may be a single, always-on, production application instance, there can be multiple environments for analytics and reporting.
When an application is archived, there is no longer a production instance, and there may be no further updates to the application code or data. But the data in production instances may need to be retained for years. Production applications can be shut-down, and copies of the data deployed in an enterprise cloud, ready to be brought up on demand, for example, in Kubernetes pods.