Solving the 3n+1 Problem with YottaDB
K.S. Bhaskar
Our goal of “YottaDB Everywhere” aims to provide rock solid, lightning fast, secure persistence wherever it is needed. This means providing standard, supported, YottaDB APIs (called “wrappers“) to access YottaDB from popular languages. This in turn leads to several needs:
- While there are certainly superprogrammers who write code using new APIs after reading the user documentation, lesser mortals, among whom this author counts himself, are more comfortable finding working code, of which bits can be copied and suitably adapted. In order to allow such a programmer to focus on the code and not get distracted by the problem being solved, it is desirable to find a simple problem with a compact solution which nevertheless uses a range of functionality provided by an API.
- Choosing the right language, implementation, and API can make it easier (or harder) to achieve the objective in situations when performance matters. Comparing programs that solve the same problem using the same algorithm make it easier to make apples-to-apples comparisons of different languages and implementations.
- Meaningful application benchmarks involve specific workloads of specific applications, workloads that are representative of situations in which application performance / throughput matter. As such benchmarks are costly to run, there is a need for simple benchmarks that are easier to run, and which can narrow down the range of full application benchmarks that must be run. A good simple benchmark is one that, based on simple inputs, can run on machines ranging from a low end system like a Raspberry Pi Zero to a high end server, execute from seconds to hours, and run on databases ranging from Megabytes to Terabytes.
- Importantly, in a software company, where many of us are proud to be geeks, we want to have fun!
Our solution to this is to create programs to solve the “3n+1” problem.
The functional goal of the 3n+1 problem is as follows:
Given an input integer i, report the length of the longest 3n+1 sequence of an integer from 2 through i, as well as the largest number encountered in any sequence. Note that multiple integers in the range may have 3n+1 sequences of that length, and multiple 3n+1 sequences may include that largest number. Also, the longest 3n+1 sequence and the largest number may or may not start with the same integer.

By providing solutions to the same problem in multiple languages, our goal is to provide working sample code as a template for developing applications, as a learning tool and as a mechanism to compare the relative performance of various implementations.
Starting with any positive integer n, a sequence of numbers (the 3n+1 sequence) can be generated as follows:
- if n is even, the next number is n/2
- if n is odd, the next number is 3*n+1
Lothar Collatz conjectured that for any finite n, there is a finite length 3n+1 sequence that ends in 1.
For example, the 3n+1 sequence for 3 has a length of 7 steps (3, 10, 5, 16, 8, 4, 2, 1) and the largest number in the sequence is 16.
Our practical goal is to illustrate the use of YottaDB’s key value store to solve this problem.
As the core functions of a database are sharing and persistence:
- There are multiple collaborating workers (processes, threads, or co-routines). By storing results in a database, collaboration allows workers to build on one anothers’ work. For example, if a worker computing the 3n+1 sequence starting with 3, finds that the length for 8 is already in the database, it can stop, and enter the results for 16, 5, 10, and 3 in the database, working backwards along the sequence to its initial number.
- The range of input numbers is organized into blocks of concurrent numbers: for example, an input range of 1,000,000 numbers can be organized into 500 blocks, each of 2,000 concurrent numbers. Until all 3n+1 sequences are computed, each worker loops to pick up the next available block and compute the 3n+1 sequences for that block.
- In the event of a crash, recovering the database and re-running the same input re-uses the results from the prior run. YottaDB ensures that the recovered database has the Consistency required for correct results from the second run (or third, fourth, or subsequent run, in the event there are multiple crashes). YottaDB’s ACID transactions are used to make the application self-checkpointing.
Until it reaches the end of the input, the program reads lines, each of which has:
- A required parameter, i, the upper end of the range for which 3n+1 sequences are to be computed.
- Two optional parameters, the number of workers (defaulting to twice the number of CPUs) and the size the blocks of concurrent numbers (defaulting to approximately the input range divided by the number of workers).
For each input line, the program produces a line of output:
- The input i.
- The number of workers.
- The block size (if the input block size is greater than the default, the program uses the default).
- The length of the longest 3n+1 sequence found.
- The largest number encountered in any 3n+1 sequence.
- The elapsed time in seconds, with a resolution of milliseconds.
- The total number of database updates.
- The total number of database reads.
- Database updates per second (total updates divided by elapsed time).
- Database reads per second (total reads divided by elapsed time).
To illustrate the use of YottaDB in-process data management (it is more than a database), even when a language implementation has packages and data structures such as hash tables, programs use YottaDB local variables.
A manager organizes the work, launches workers, and reports results when all workers are done. In order to minimize artifacts from launching workers (an activity in which YottaDB plays no part), each worker waits till the manager indicates that all workers are launched, before starting its work. The manager then waits for all workers to complete before it can report results. Where the manager and workers are processes, this coordination is accomplished with YottaDB’s hierarchical locks. Since YottaDB locks are resources owned by the process, in implementations where the manager and workers are threads or co-routines, coordination is achieved using non-YottaDB mechanisms.

Although quick and easy, the 3n+1 technique has limitations, especially when it comes to using it for benchmarking and performance tuning:
- It is update intensive: about 40% of its database accesses are updates. Perhaps 10-20% of database accesses in an update-intensive workload from the “real world” are likely to be updates.
- It is database access intensive: it performs minimal computation for each database access. A real application would most likely perform one or more orders of magnitude more computation for each database access.
- Database accesses are small: except for cross-references, the data transferred in each database read or update would be much larger in a real world application.
Of course, most importantly, what you care about is not the performance of 3n+1 programs: you care about your application, with a critical workload for that application. Nevertheless, the 3n+1 programs are an important tool for learning and benchmarking toolboxes.
In the future, we anticipate blogging about actual results from our 3n+1 programs which we will make available so that you can run them. Meanwhile, please do send us your comments.
Images Used:
[1] A graph, generated in bottom-up fashion, of the orbits of all numbers under the Collatz map with an orbit length of 20 or less
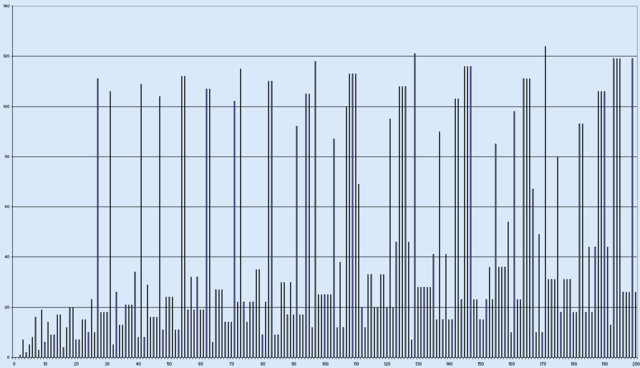
[2] A graph with the value of the number of steps to reach 1 applying Collatz procedure to numbers between 2 and 200.
[3] Collatz Conjecture, XKCD
[4] The Collatz map can be viewed as the restriction to the integers of the smooth real and complex map. Iterating the optimized map in the complex plane produces the Collatz fractal.
Published on January 14, 2019