
AI for M Patterns
Alex Woodhead
We thank Alex Woodhead for his first blog post, and hope there are many more to follow. If you would like to post on the YottaDB blog please contact us at info@yottadb.com.
TL;DR
Generating patterns for string pattern matching in the M language is expert friendly. An AI tool eases the task. There is a live demonstration where you can try it for yourself.
Using AI to Generate M Patterns
Programs need to determine whether a string matches the pattern for a specific type of data. For example:
| Data Type | Example |
|---|---|
| info@genput.com | |
| Phone Number | 213-101-0101 |
| Date | 06-07-2025 |
Pattern matching allows M (affectionately known as MUMPS) language code to determine whether a string matches a pattern, for example, whether a line of input contains a telephone number, an e-mail address, a date, etc. For example, 1"("3N1")"2(1"-"3N)1N matches a US telephone number in one common format, e.g., (123)-456-7890.
As the syntax of M patterns can be arcane, this blog post describes an AI generative pretrained transformer (GPT) for generating the code for M patterns from natural language input as well as sample datasets.
Patterns can be generated from natural language descriptions or from examples.
Patterns from Descriptions
A natural language description of a telephone number in the format (###)-###-#### where # is a digit could be:
module A one of character minus followed by three of numeric characters the main pattern is as follows: one of character open-parenthesis followed by three of numeric characters followed by one of character close parenthesis followed by two of module A followed by one of numeric character
Natural language descriptions aim to be readable and understandable without technical training. Updating a textual description is more user friendly and less error prone than manual pattern match code. The technical demonstration uses generative AI to transform these text descriptions into M source code code, thus making existing pattern match code accessible for maintenance and support.
Patterns from Samples
Consider the following sample records:
| Item | Record |
|---|---|
| 1 | (003)-615-2614 |
| 2 | (519)-523-0258 |
| 3 | (266)-885-4964 |
| 4 | (261)-274-3909 |
| 5 | (752)-129-3876 |
| 6 | (173)-514-2497 |
| 7 | (040)-511-8991 |
| 8 | (467)-715-3325 |
| 9 | (488)-269-8099 |
| 10 | (025)-705-8417 |
An author of pattern match code may follow a development process:
- Review the sample records for format features:
- Numeric sequence length
- Open and Closing Brackets
- Hyphen delimiter
- Decide the characteristics of format rule elements to use.
- A rule can be defined in different ways.
- Which approach is elegant, optimal and maintainable?
- Implement Pattern Match code to encapsulate the format.
- Test the code against code samples.
What if AI could replace these steps and create pattern match code automatically from the same data samples? The technical demonstration replaces all manual steps 1 through 4 above with automatic code creation.
Finally this technical demonstration closes the development iteration loop for pattern match code by offering:
- Generating natural language descriptions from existing pattern code.
- Generating compliant samples and anti-samples from existing pattern code.
Building Models
In early model training cycles it was found that the features for description-to-pattern were incompatible with samples-to-pattern challenges. Hence development then proceeded to create two separate models, one for each task area.
Description-to-Pattern Model
A synthetic dataset was created consisting of sets of pattern match codes followed by their respective descriptions. An extensive balanced representation, and randomized variation of pattern features was needed to learn:
- Repetition range, e.g., “One-To-Three” numeric characters
- Structure
- Optionality
- Alphanumeric, Numeric, Punctuation
- Literal strings
For model description text, multiple sample variations are introduced to anticipate flexibility for prompt input for example:
- Quantity alias: “two” can be represented in similar words like “Double”, “Twice” and “Pair” or the value “2”
- Character alias: “-” and the word “minus” can be used interchangeably.
By introducing description variation in named written natural languages, a single assimilated model can process prompts in multiple languages.

Samples-to-Pattern Model
Another synthetic dataset was created consisting of sets of sample values followed their respective pattern code. As before an extensive balanced representation, and randomized variation of pattern features was needed to learn:
- Repetition range: “one-To-three” numeric characters
- Structure
- Optionality
- Alphanumeric, Numeric, Punctuation
- Literal strings
Additionally the dataset is balanced for:
-
- Generalization
- Prefer generating exact patterns for small data samples
- Prefer generating flexible patterns for samples with wide variation
- Delimiters, for example:
- Character
"-"in text"(003)-615-2614" - Character
"^"in text"Smith^Bob^M^19340815"
- Character
- “Open-Close” pairs features for example:
"("and")"in text"(003)-615-2614""<"and">"
- Generalization
To clarify and elaborate on how the term “generalization” is being used here: In model training there are the concepts overfitting and underfitting. If a model is over trained on a sample dataset it does not perform well for future tasks on new samples not in the original training dataset. There is a similar scenario for the completed PatternMatch model. The model needs to suggest from a small number of sample records, the likely useful pattern match expected. Some patterns can represent tens of thousands of variations of possible samples. Some patterns are very specific with only a few possible samples that all fit in the prompt supplied to the AI. The training data is deliberately curated to provide a wide and graduated range of exact to more generalized patterns. This appears to imbue a logical “pattern usefulness”.
To postulate how the model may achieve this, consider the next possible generated character when outputting software code. This has a constrained range of possibilities.
- In samples where the association of the next token in sequence is weighted to relate to only a small number of possible tokens, this deep feature then suggests generating patterns with small number of possible samples.
- In samples where the association of the next token in sequence is weighted to relate to a wider variety of possible tokens, this deep feature is cascading to prefer generating more general patterns for large possible samples.
The term generalization is wrapping the spectrum of this behavior. The process is not using a human chain-of-thought reasoning to achieve output, but a more fundamental set of self-taught features, impressed during training.
Samples are required to fit within the context window of the GPT. Randomized variation in the number of sample records within each training item, improves deduction capability at low sample numbers. Empirical benchmarking is used to evaluate performance for Generalization vs Delimiters style patterns.

Within the pipeline, two forms of pattern were tracked, where one is a simplified form. This endows generative behavior with a preference for shorter pattern forms, e.g., consider rule “two numeric followed by two to four numeric” can be more simply expressed as “four to six numeric”.
Training Effort
Environment: Nvidia Cuda A10 GPU on the Huggingface platform.
Description-to-Pattern Model
A full retrain is needed when incorporating each new language.
| Stage | Continuous GPU training |
|---|---|
| New dataset | 4 days |
Samples-to-Pattern Model
| Stage | Continuous GPU training |
|---|---|
| Prototype base dataset | 4 days |
| Main dataset | 13 days |
| Second refined dataset | 2 days |
| Third refined dataset | 4 days |
As the models are separated by task, it becomes convenient to add new language support to descriptions with a relatively quick turnaround.
Benchmarking
Complete success of a pattern match was defined as its ability to satisfy all of its respective candidate sample records, not just those that fit within a context window.
Overview Benchmark Report
| Total benchmark tests used | 3895 |
|---|---|
| Mean success across all matches | 91.75% |
| Complete pattern match success | 81.98% |
| Partial pattern match success | 15.74% |
| Unsuccessful match records | 2.28% |
The following table gives examples from benchmark candidates demonstrating partial success. It shows the percentage of sample records successfully matched to generated pattern code.
| Item | Sample Size | Context Window | Rows Matched | % Match | Actual Generated Pattern | Pattern Template |
|---|---|---|---|---|---|---|
| 1 | 31 | 31 | 28 | 90.3 | 4UN5AN2.3(4UNP2"/"1UP... |
4UN5AN2(4PUN2"/"1PU... |
| 2 | 31 | 31 | 17 | 54.8 | 5N5ANP3"7Æ6N1ŃS8"1(2... |
5.6N5NPA3"7Æ6N1ŃS8"... |
| 3 | 31 | 24 | 15 | 62.5 | 5.8"6Ã02"1.2LNP1.2(1"K"4... |
5.8"6Ã02"1.2LNP1.2(1"K"4... |
| 4 | 31 | 19 | 28 | 90.3 | 3P5UN5NP5UN5UN3AN3... |
3P5NU5NP4UN5NU4NA... |
| 5 | 31 | 10 | 7 | 22.6 | 4LNP3.6AN4"×_"5"¤īĩĵ®ü"... |
4NPL2.5NA4"×_"5"¤īĩĵ®ü... |
| 6 | 30 | 9 | 26 | 86.7 | 5.6"ŀ¬¦"5"!pp%"1UNP5"Ù6... |
5.6"ŀ¬¦"5"!pp%"1PNU5"Ù... |
| 7 | 25 | 12 | 5 | 20.0 | 2"AAHH"5"30"3(4.7UP,4L)... |
2"AAHH"5"30"5(3UP,4L,4... |
| 8 | 31 | 14 | 30 | 96.8 | 5LP4")))¦¦§÷"4.10LN5.10U... |
5PL4")))¦¦§÷"4.11NL5.10P... |
Column Explanation
- Sample Size – The number records available for test sample. Sometimes a pattern describes less than 31 possible exact matches.
- Context Window – Maximum number of sample records used by model to generate a new pattern.
- Rows matched – This is the number of ALL sample records that were matched by the generated pattern. This may be larger than the actual context window.
- Rows matched – Percentage of Rows Matched divided by Sample Size.
Items 4, 6 and 8 all achieve a match count greater than the context window. When pattern match code is generated from sample values the context window used and proportion of matching is returned and displayed as a comment in the technical demonstration.
Front-end Framework
The technical demonstration employs a Gradio web framework as the web display layer. This fits well with HuggingFace ecosystem and infrastructure choices. It provides both a browser displayable layer and a callable API. The callable API is used by benchmarking scripts to leverage cloud GPUs to effect faster report turnaround. The Gradio framework provides a low code user interface implementation approach, freeing more time to focused on domain specific training challenges. For example, in a Python virtual environment with CUDA available, one can translate from English to French, in just a few lines of code:
from transformers import pipeline
import gradio as gr
pipe = pipeline("translation", model="Helsinki-NLP/opus-mt-tc-big-en-fr",device="cuda")
demo = gr.Interface.from_pipeline(pipe)
demo.launch(server_port=8080)
This renders the following fully operational web interface for translation:
The following screenshot shows the more involved demo tool interface utilizing the same Gradio framework:
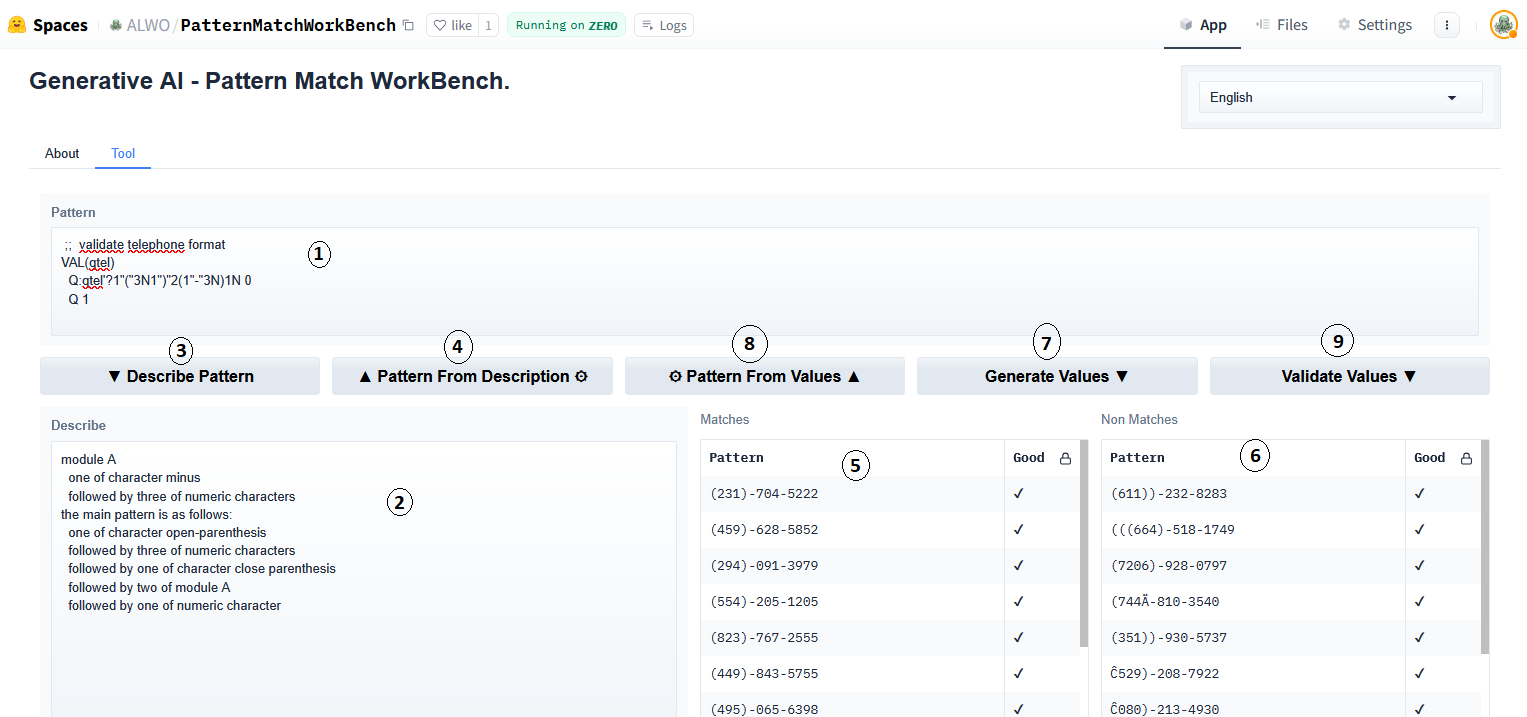
Legend:
| Item | Control | Description |
|---|---|---|
| 1 | Pattern Text | One or more lines of M code. The pattern can be extracted from the first line containing a pattern match expression. |
| 2 | Describe Text | This holds a structured description corresponding to code code expression pattern. |
| 3 | Describe Pattern Button | This button action transforms the pattern in code into a human readable structured description. |
| 4 | Pattern from Description | This button action uses generative AI to translate the natural language description found in English, French, Spanish, or Portuguese into new pattern match code. |
| 5 | Matches List | Sample values that match the code expression. |
| 6 | Non-Matches List | Sample values that fail to match the code expresion. |
| 7 | Generate Values Button | This button action extracts the pattern in code and generates the two lists of matching and non-matching values. |
| 8 | Pattern from Values Button | This button uses generative AI to transform the values in the “Matches” column into a new pattern match code expression. |
| 9 | Validate Values Button | Re-validates all the sample values in both the “Matches” and “Non-Matches” columns. |
The “tick” and “cross” symbols in the “Good” column, confirm expected sample result for “Match” or “Non-Match” context. The use of “tick” and “cross” was chosen to communicate purpose in a mixed language user interface. The “gear” symbol on buttons is used to convey which parts of the user interface employ generative AI functionality.
Example of user workflow steps for the use-case to adjust an existing pattern match expression:
| Step | Description |
|---|---|
| 1 | Paste lines of code into “Pattern” text input. |
| 2 | Press “Describe Pattern” button. |
| 3 | Adjust or extend natural language description in chosen language (English, French, Spanish, Portuguese). |
| 4 | Press “Pattern from Description” button to generate new pattern code. |
| 5 | Press “Generate Values” button for new random testing values to explore and refine matching behavior. |
| 6 | Edit and add new samples in “Matching” and “Non-Matching” lists |
| 7 | Press “Validate Values” button to confirm adjusted sample values all pass as required. |
Internationalization
In order to provide to runtime switchable language in the web interface, the community Python package gradio_i18n was employed. Label values are defined in a static dictionary keyed by language. The fiddliest part in demo was getting column titles updating when language changes.
For description training data, a different approach is needed that also incorporates tracking for:
- Single or Plural quantities.
- Gender, e.g., French has words “un” and “une” for number one.
| English | French |
|---|---|
| a table | une table |
| a candlestick | un bugeoir |
In Spanish, the plural address differs.
| English | Spanish |
|---|---|
| the tables | las mesas |
| the Cars | los coches |
For language specific error and informational messages, Python format strings are employed instead of composition. For example the info message placeholder: “info_X_of_Y_rows_used”:
| Language | Python Format String |
|---|---|
| English | "{} of {} rows used." |
| French | "{} de {} lignes sont utilisées" |
| Spanish | "utilizan {} de {} filas" |
| Portuguese | "{} de {} linhas são usadas" |
Application Tricks
Retry and Context
When using a list of values to deduce a pattern, the order of the supplied values can influence the model success. To game this, there is a server-side retry-loop that shuffles the values in the context window. Attempting up to 5 times to find a fully matching pattern as validated against ALL of the sample values. It stops at the first full match.
When only a subset of sample values fit in the context window the returned pattern will include a description of the number of rows of samples used. This gives a hint and opportunity to promote specific rows into the context window for a better inference.
Generated patterns are validated against the whole list of patterns. Where this is a partial success pattern suggestion the number of sample rows that do match will be quantified and displayed in code comment.
Future Opportunities
The YottaDB and GT.M pattern match operator offera an extensibility mechanism. Similar to how pattern match code letters ANP mean Alphanumeric, Numeric and Punctuation respectively. Additional letters can encode context specific meanings. Should there be a commonly accepted usage of extensibility for a particular set of applications, it may be possible to tailor an additional trained model to accommodate these features.
About Alex Woodhead
An M programmer with almost a quarter century of experience, Alex Woodhead has worked on projects relating to clinical information system projects on multiple continents. Now living in Southern California, he is focused on synthetic data pipelines for generative AI for novel tools and automation, and is incubating genput.
Contact: info@genput.com
-
-
- Picture of Hunting Carpet made by Ghyath ud-Din Jami, Wool, cotton and silk, 1542–1543, Museo Poldi Pezzoli, Milan. This file has been identified as being free of known restrictions under copyright law, including all related and neighboring rights.
- Blog roll picture generated by OpenArt in response to a prompt by K.S. Bhaskar.
- Alan Turing quote from https://mathshistory.st-andrews.ac.uk/Biographies/Turing/quotations/
- Other graphics provided by the author.
-
Published on August 15, 2025